JavaScript Interview Questions
This article contains some of the most commonly asked JavaScript interview questions, and they are all rooted in the fundamentals. If you understand these, you will have the intuition and JavaScript foundation to perform well in interviews.
This module also contains advanced JavaScript interview questions, including:
This article has two goals:
- Test essential JavaScript knowledge and core fundamentals that are likely to come up in interviews
- Give examples of common questions. Some of these are "good" and some are not, but they are still asked frequently, so you need to know them.
Questions
JavaScript is a loosely typed language which means we don't have to declare a variable's type at creation, and a variable can change types throughout the lifetime of the program.
Because of this loose typing, JavaScript introduced two ways to compare variables with === and ==.
To a computer, the characters 2 and "2" are entirely different. In JavaScript the first is considered a number type and the second is a string type.
Using the === operator, we are trying to determine if two items are exactly equal or "strictly equal", which means they must match in type and value.
If we instead use ==, JavaScript will try to coerce the values (convert them to the same type) and then compare them.
The intention here is that we only care if the values are similar, even if they are not originally the same type, also called "loosely equal".
For 2 == "2", JavaScript converts the "2" to a number 2 before checking if they are equal which is why we get true.
The === comparison is almost always favored over == because it is more explicit and prevents unintended bugs.
If you need to make comparisons in your interview code, I would highly recommend to never use == or be prepared to make a strong argument for why you did.
The following are some of the weird cases where JavaScript tries to convert values and compare them:
These would all return false if the === operator was used.
The this keyword in JavaScript is one of the language's' most difficult topics.
Even if a developer knows the theory behind this, it can still be challenging to work with in real code.
Explaining this fully would require a book.
The this keyword allows us to refer to the object that executes a method.
In the example above, we create an object and use the this keyword inside of it to reference the object itself.
It allows us to access data and methods on the object.
The most difficult part of understanding this in JavaScript is that its value is determined by where the function is called that uses this.
So even if you define this to work a certain way, it can still change at any point in your program.
There are six rules to help you determine what the value of this will be.
- When you create an object using the
newkeyword with a constructor function/class,thiswill refer to the new object inside the function. - Using
bind,call, orapplywill override the value inside a function, and you can hardcode its value forthis. - If a function is called on an object as a method,
thiswill refer to the object that is calling it. For example,myObject.method()would have a value ofthisthat refers tomyObject. - If a function is executed without any of the three previous criteria being applied,
thiswill refer to the global object, which iswindowin the browser orglobalin Node. If you are using strict mode,thiswill beundefinedinstead of the global object. - If multiple rules from above apply, it will use the rule that comes first in this list.
- Arrow functions ignore all the above rules, and the value of
thisis determined by the scope enclosed by the arrow function.
In interviews, what you will most often be tested on is:
- Giving a simple explanation of
this - Set the value of
thisusing one of the JavaScript rules - Fix code where
thisisn't working as expected - Build an object that uses
thisinside it
All three of these methods can be used to set the this value of a function.
There are some subtle differences in how they work though.
bind
This is used to set the this of a function, but does not invoke the function immediately.
Instead, it returns a new function with the this value set.
So the value returned is a function you can execute later where the this is forced to take the value of the object that you called with bind.
call
The call method will execute a function immediately, and the first parameter is the object that is set as this. All the arguments after it will be passed to the function.
apply
The apply method will execute a function immediately, and the first parameter is the object that is set as this. The second parameter is an array whose items will each be passed to the function as arguments.
call vs. apply
Both of these execute the function immediately.
The primary difference is that call will take an arbitrary number of arguments. The first parameter is the value set to this. The remaining arguments will be used as parameters in the executed function.
The apply method only takes two arguments. The first argument is the value to set this. The second argument is an array that is passed to the executed function as individual parameters.
Sometimes these methods are simply used to execute a function, and if the this content is not necessary, you can use null as the first argument.
The var variable declaration is typically viewed as a legacy pattern.
It creates a variable that is function scoped and can be reassigned at any time.
If a var variable is declared outside of a function, it is part of the global scope and will be a property on the global object.
The let keyword was introduced in ES2015.
A variable declared with let can be reassigned at any time, like a var.
The primary difference between let and var is that let is block scoped which means it is only available within a {} (including functions).
The const keyword is used for constant variables and can only have one value ever assigned to it.
An error will be thrown if we try to reassign a variable created using const.
Like let, a const variable is block scoped.
Since JavaScript is a loosely typed language, we can use variables of any type and JavaScript will try to coerce them (transform their type) to whatever is needed in a particular situation.
For example, an if (conditional) {...} statement is expecting a boolean, but you can pass any variable type to it, and it will still work.
What is happening is that JavaScript is converting the string above to a boolean. A string containing characters is converted to true and an empty string is converted to false.
Then the if statement handles the resulting coercion.
Every variable type is converted in this manner.
The values that convert to true are considered "truthy".
The values that convert to false are considered "falsy".
Below is a list of all the falsy values in JavaScript. Everything else is considered truthy.
It's worth noting that empty arrays [] and empty objects {} are considered truthy.
Arrow functions offer a few advantages:
-
A more concise and compact syntax.
() => {}vsfunction() {}. -
Implicit return if the function is one line. You can leave out the function body and JavaScript will automatically return the value.
- A key benefit is how arrow functions handle
this. Previously, usingfunctionbound the value ofthisbased on where the function was called. This forced developers to add hacky fixes to retain the originalthisvalue. On the other hand, an arrow function does not create its ownthisand instead uses the value from its enclosing scope.
Other notable differences include:
arrow functions don't have access to the arguments object,
arrow functions don't change this from bind/call/apply since they don't define their own value for it,
and arrow functions can't be used as constructors functions with the new keyword.
A ternary operator means there are three operands: 1 ? 2 : 3
It is similar to an if-else statement: condition ? ifTrue : elseFalse.
One difference to note is that inside an if-else statement, you execute code,
but with a ternary operator, it returns either the first or second value and can be assigned to a variable.
The example below performs equivalent operations:
Closures can be confusing for newer developers, but once the concept "clicks", they become very intuitive. The two features of JavaScript that enable closures are:
- Lexical scoping (variables take on values based on where they were declared)
- Functions as first-class citizens (specifically, a function is almost always returned as a value from another function to create the closure)
The key to forming a closure is returning a function from another function. This returned function now has access to all the variables of the outer function because it is part of its scope. The values of the variables persist, and can be both read and updated.
The event loop is the foundation of how JavaScript executes code. You may or may not be asked this directly, but the concepts will be helpful regardless. Understanding the event loop will not only help for interviews, but also make you a better JS developer overall.
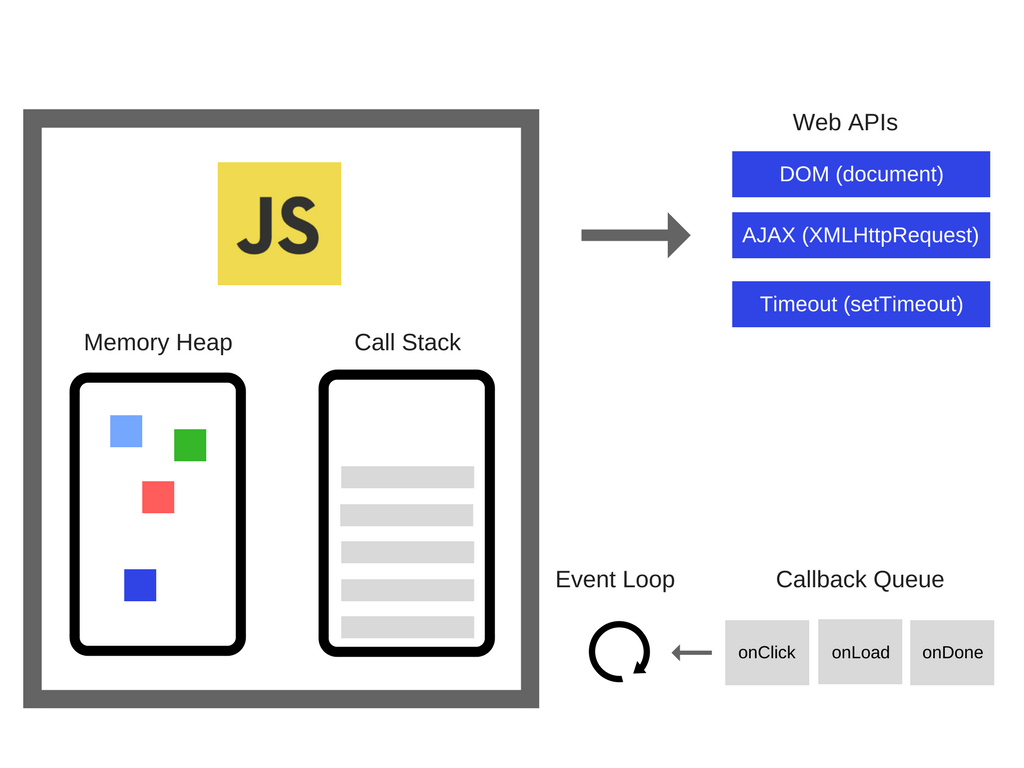
The two terms you would want to mention are the "call stack" and the "event queue".
- Call Stack: Where our main program runs synchronously
- Event Queue: Where the callbacks of asynchronous code run once the stack is clear
- Event Loop: Watches the stack. When it's empty, it grabs the first item in the event queue and passes it to the stack to run
- Heap: Where we store our objects and variables in memory
You may have heard that JavaScript is "single-threaded non-blocking IO". When we say JavaScript is single-threaded, it means the main program runs in-order, line-by-line on a single thread, by adding items to the stack. However, when we say it's non-blocking IO, this means thats tasks which aren't part of our main program are actually pushed off to another thread to be handled concurrently. The result is passed to a callback and added to the event queue to handle once the stack is clear.
If you haven't watched this video by Philip Roberts, it's essential content for any JS developer.
Jake Archibald also gave an equally excellent talk on the topic.
In JavaScript, functions are first-class citizens, which means they can be treated like any other data type. A function can be assigned to a variable, passed as an argument to another function, or be the return value from another function.
An anonymous function means we use a function without declaring or naming it. The most common example of this in JavaScript is a callback function where we pass an anonymous function as an argument to be executed inside another function.
If a variable is declared in the global scope, it is available to all the code in an app, which can cause collisions and difficult bugs. JavaScript is a function-scoped language which means that variables declared in a function will only exist in that function. Anonymous functions declared as IIFEs would allow us to run code without polluting the global scope.
This is a deep topic that takes a book to understand fully.
I'll give a synopsis of how to understand it for an interview,
but I highly recommend "YDKJS: this & Object Prototypes" for completeness.
Plus it's free on GitHub!
To understand prototypes, it's probably best to first explain class inheritance vs. prototype inheritance.
Classes (in Classical Object-Oriented Languages)
A class is how most other object-oriented languages (such as Python, Java, C++) share functionality. Classes are a blueprint for how to create an object, and to inherit its functionality in a child class, you copy all of the methods and properties over. They are then duplicated in the child.
Classes themselves are not objects, but define the properties and methods an object will have.
NOTE: The JavaScript
classkeyword is not an actual class like in other languages. It is still just a wrapper around prototypes but uses syntax that will feel similar to other languages. Declaring aclassis actually just a constructor function that makes it easier to manage properties and the prototype.
Prototypes
In JavaScript, we don't use classes as a blueprint. We use objects themselves to share properties and methods. This means we do not make copies. Instead we link to an object through the prototype chain to indicate we want to utilize a parent's functionality.
Every object in JavaScript has a __proto__ property which points to the object it inherits from.
The object it points to also has its own __proto__, which points to its parent.
This is how we create the prototype chain — each object points to the object it inherits from until we reach the Object that sits at the top of the prototype chain.
If we try to call a method or property on an object we create, but it doesn't exist on our object directly, JavaScript will then walk through the objects in the prototype chain to see if any of them have it.
Benefits of Prototypes
One of the primary benefits of using prototypes over classes is that we don't duplicate properties on children, and this drastically reduces the memory footprint.
We just have a single object for each level of inheritance that is referred to when we need functionality.
For example, when you create a React class component class MyComponent extends React.Component, each one just points to the Component object instead of copying over all the methods
for every single component you make in your app.
Another benefit is that there is less coupling. We can compose objects to group functionality instead of bolting it to class. This approach can actually be much simpler and also more powerful, once you understand prototypes and how they work.
Prototypes are also easily extended. For example, when a new version of JavaScript is released, we can easily modify and polyfill new functions on existing objects.
Prototype Example
An easy way to use prototype inheritance and set an object's __proto__ is through the Object.create function.
It creates a new object with the __proto__ set to the value passed to create.
new and prototype
A final note is that prototype is actually a property of functions that are used as constructors.
For all objects created using the new keyword with this constructor function, their __proto__ will point to the prototype of the constructor function.
This would be very similar to using a class in JavaScript since a class is just a constructor function that helps us manage objects and the prototype chain.
In fact, you could run the same code above and just replace the function Person(name, age) { /* ... */ } constructor with the class Person { /* ... */ } class.
If we wanted to use inheritance, we could use the extends syntax, like class Friend extends Person {/* ... */}. This helps us manage the prototype chain underneath the hood.
Variables declared using the var keyword or functions declared using the function keyword will have their declarations moved to the top of their scope.
So in the example above, even though we declared hello after the first console.log, it still recognizes the variable as existing but just undefined.
Hoisting means JavaScript actually moves the var hello; to the top of the file which gives it an initial value of undefined.
Then when the code execution actually reaches the original var hello = 'world'; it just assigns the value for the first time.
This is in contrast to let and const, which are not hoisted.
You will receive a reference error saying the variables are not defined and the program will crash.
Both the browser (window) and Node (global) have a global outer scope that is managed by a global object.
Variables and functions declared in the global scope are available anywhere in your code.
Standard library functions we use in our program are actually stored on the global object:
If you declare a variable or function at the top-level, it actually becomes a property on the global object.
Declaring a variable with
letorconstdoes not add it to the global object.
We should be careful when adding variables to the global object because it can cause collisions and unexpected bugs that are hard to track down. For example, a common issue is two modules that are expecting a different value stored in the same global variable name.
JavaScript treats functions as first-class citizens which allows for some very powerful patterns. A higher-order function takes another function as an argument and/or its return value is also function.
Common examples of this include:
- Anonymous function arguments
- Closures
- A callback function to handle the result of an asynchronous call
- A callback to dictate how a function should execute, such as
arr.map(x => x * x) - Function currying, where the returned value is another function that can subsequently be executed
These three values may seem similar but actually have very different impacts on our code.
null: declared and explicitly assigned an empty valueundefined: declared and not assigned a value- undeclared: trying to use a variable that was never declared
null
If a variable is set to null, we are explicitly saying this value is empty.
Properties in JSON objects can be set to null, and it will persist through an HTTP request.
If another programming language uses the same JSON object, they will have their own null construct to handle the value.
In JavaScript, if we have default function parameters and pass a null input, it will use the null and not the default.
undefined
An undefined variable means it has been declared but not assigned a value (as opposed to null which has explicitly assigned the value).
If there is an undefined value in an object that is converted to JSON, it will remove this property.
When using default function parameters, if there is no value passed, it is viewed as undefined and will use the default value.
Developers often use
typeof x === 'undefined'to check forundefinedbecause it won't throw an error if the variable is actually undeclared.
undeclared
Undeclared is the terminology we use to describe when we try to use a variable in our code that was never declared at all.
Short circuit evaluation is a technique where you use binary logical operators to avoid unnecessary work. It can also be used to assign variables based on the truthy or falsy values used.
A truthy value means that the value is coerced to true,
and a value is falsy if its value is coerced to false (for example, an empty string '').
Binary logical operators will look something like the following:
The OR || operator will return item1 if it is truthy, otherwise it will return item2.
We use the || to short circuit by being able to skip to the second item if the first is true.
The AND && operator will return item1 if it is falsy, otherwise it will return item2.
We use the && to short circuit by being able to skip the second item if the first is false.
This is also a common pattern for conditional rendering in web applications.
The nullish coalescing operator ?? was released in ES2020.
It is similar to || but instead of considering all falsy values, it only yields to item2 if item1 is either null or undefined.
The Math.max method takes an arbitrarily long list of parameters and returns the largest.
We instead want it to work with an array.
The above returns NaN, so we'll write our own function arrayMax that still uses Math.max to find the largest number in an array.
The simplest solution is the spread operator ....
It will decompose an array into its individual items.
This question has historically been used to test an understanding of apply.
It will pass an array as individual items to a function.
Math.max is also a static method which means it is called without instantiating an object and does not require access to this, so we pass null as the first argument.
function Car(){}declares a functionconst car = Car()executes a function and assigns its return value (which can be anything) to thecarvariableconst car = new Car()creates an instance of aCarobject and assigns this object tocar
It's also worth noting that we could do something like const car = () => {} or const car = function(){} which assigns a function expression to a variable.
When laying out a web page, all the elements are treated as rectangles which we call boxes. CSS determines the position, size, and style of a box.
A box is comprised of margin, border, padding, and content.
margin: The outermost area of a box. It enforces the distance (empty space) a box wants to have from its surrounding neighborsborder: The border is the outer edge of the element and sits inside the margin.padding: The empty space inside of an element between the edge (border) and the content of the element.- content: This contains the real content of an element/box which is the text, image, video, etc.
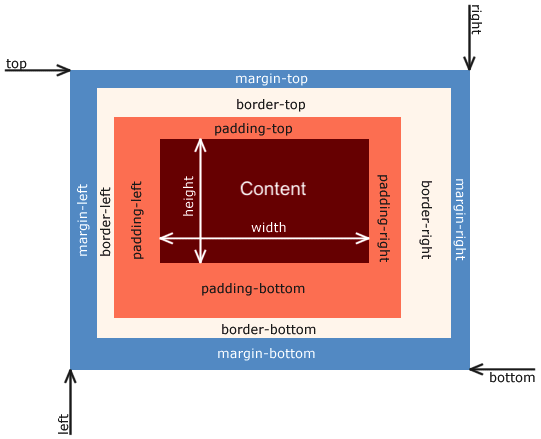
The box-sizing property is used to indicate how we want to determine the size of a given box.
Web development primarily uses box-sizing: border-box; where the border and padding are included in an element's width and height size.
AJAX stands for "asynchronous JavaScript and XML" and is a core feature of modern web development. It allows us to create fast, dynamic, and interactive web applications.
AJAX is how we make API requests from the client to send and receive data within a page.
In the client/browser, instead of needing to transition pages, reload the current page, or submit a form to change the state, we can make HTTP requests asynchronously to send and receive data between the client and a server. This allows us to decouple the presentation layer from the data layer to create powerful web applications. We can update parts of the page by exchanging smaller amounts of data with the server without needing to rebuild the entire page.
When we talk about making an API request on the client, it is doing so through AJAX.
JSON has replaced XML as the primary data exchange format and has become the standard.
When AJAX was first introduced, the XMLHttpRequest pattern was used to facilitate AJAX requests,
but now the more modern method is to use fetch or some similar promise-based library.
DOM stands for Document Object Model. A web page is just a text document written in HTML, and the DOM is the data representation of this HTML document using objects to describe its structure and content. The DOM treats the HTML document as a tree data structure where each node is an object that represents a part of the document.
The DOM can be represented using any programming language (since at its core, it's just a data structure), but we most commonly think of it in JavaScript since that is the programming language of web browsers. The DOM allows programmatic access to its tree by exposing methods that allow us to update the structure, style, and content.
- The DOM is the standard with which we represent a web page as a data structure
- The DOM is a tree data structure
- The nodes in the tree are JavaScript objects
- The objects expose methods and data about a particular section of the web page and allow us to interact with and update it.
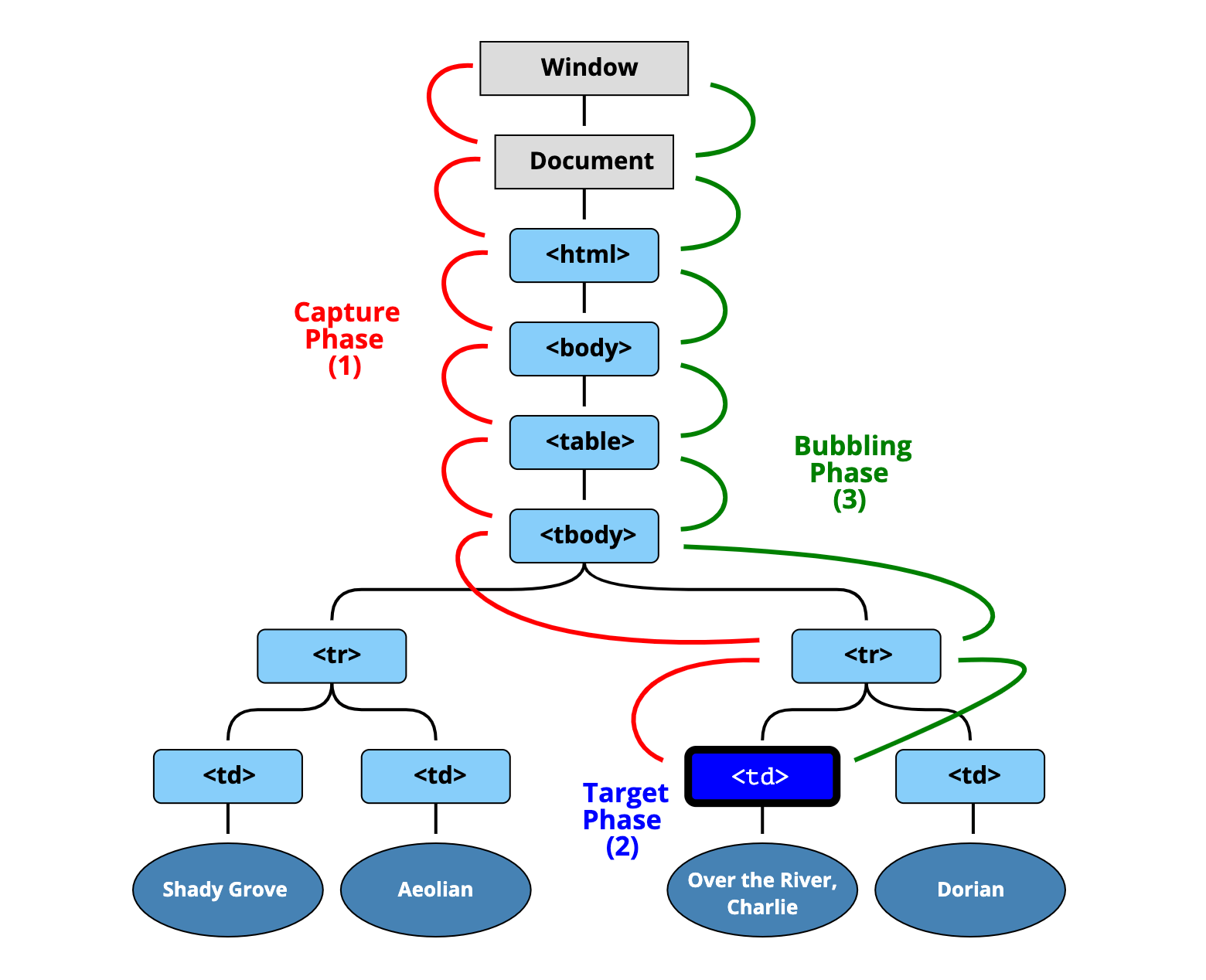
Event bubbling is part of the process where a browser captures user interaction, such as a click event or a keyboard event.
The DOM is a nested data structure where the window is the root, the document is its child, and every node on the web page are children underneath them. So when you click an element on the page, you have also clicked all of its parent elements as well. The browser then determines which element you intended to click.
There are three phases of a browser event:
- Capture: The event starts at the window and traverses through the DOM until it reaches the most deeply nested element that you clicked.
- Target: The event reaches the target element.
- Bubbing: The event bubbles up from this target and returns to the window to denote the completion and handling of the event.
The bubbling phase is when we actually execute the callbacks based on an event, such as an onclick, so this is typically the phase we're most concerned about.
Bugs can arise from event bubbling when we have an event handler on a parent of the intended target node. The target will execute its callback, and then the parent will execute its callback as well unless we stop the event from bubbling up to it.
The browser may also have some default intended behavior when a certain event is triggered on an element, and we may wish to prevent that as well.
To block default behavior or stop an event from being handled by parent nodes, we have the following functions:
preventDefault(): Prevent the browser from executing its default behavior from an event. For example, clicking a checkbox and executingpreventDefault()will stop it from checking and unchecking.stopPropagation(): Stop the propagation of an event from continuing in either the capture or bubbling phase.stopImmediatePropagation(): Stop the propagation of an event from continuing in either the capture or bubbling phase AND stop any further events that are being handled on the current element.
Event delegation is when you attach an event listener to a parent instead of its children.
For example, imagine you had a list <ul> with 10000 children <li> nodes.
If you were to attach an onclick handler to each <li>,
it could require the browser to use significant resources to create, maintain, and remove all of these.
On the other hand, you could attach one onclick handler to the <ul> element.
Then if you were to click an <li>, you could recognize and handle this event during the bubbling phase.
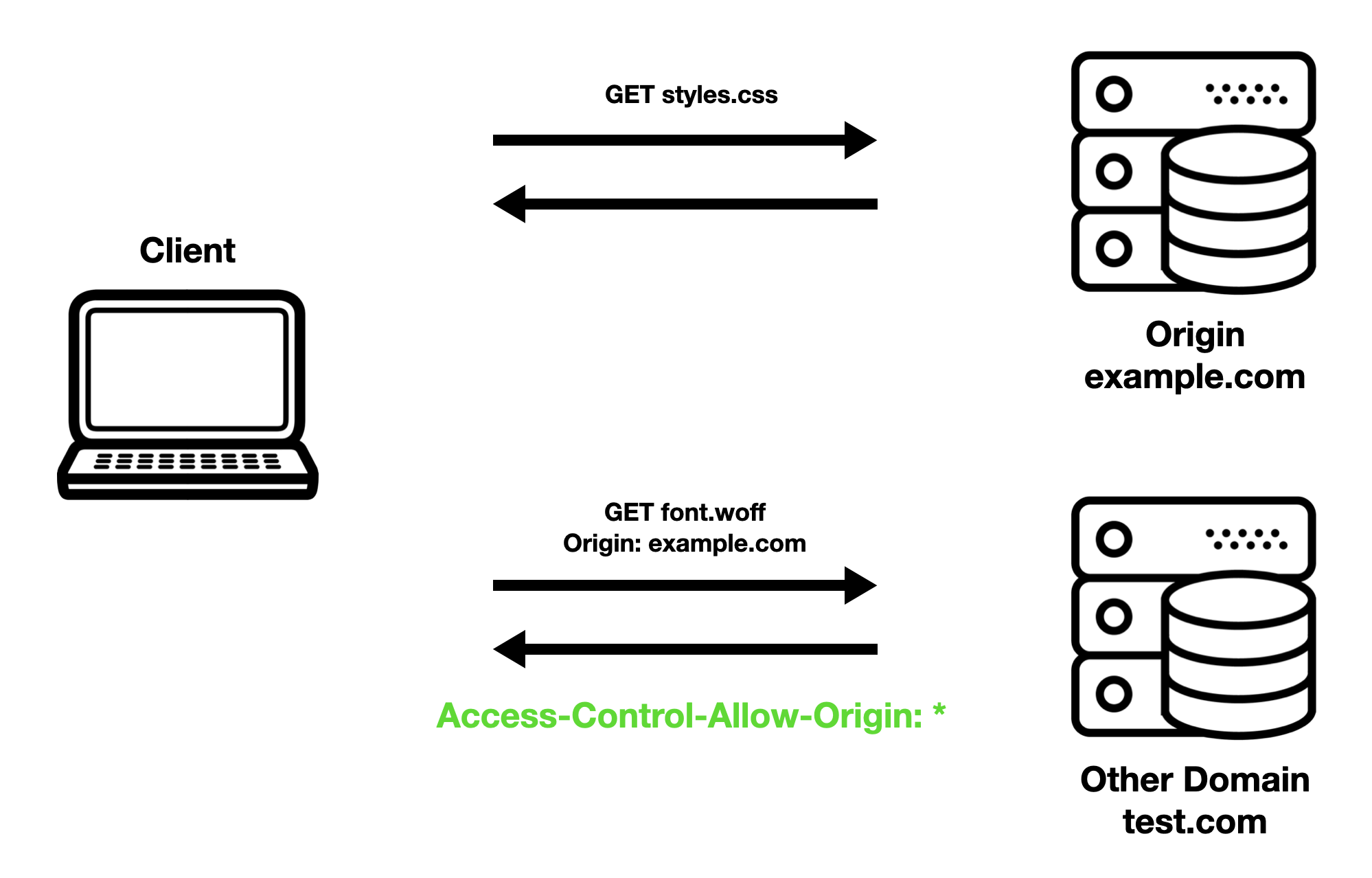
CORS stands for "cross-origin resource sharing" and is a mechanism allowing us to access resources from other domains (origins).
It specifically refers to how a client connects to servers.
CORS determines how a browser is able to utilize files/data from domains outside a user's current URL.
Because a website loads resources from all around the web, the same-origin is used to mitigate risk and prevent hijacking a user's visit.
For example, if you are on facebook.com, you are able to download all the HTML, CSS, JavaScript, font, and image files from them.
In addition, the browser won't block you from accessing an API like facebook.com/api/users.
However, if you try to access data from a domain outside of Facebook while still on the site, such as calling the Twitter API twitter.com/api, you may or may not be able to fetch this data depending on how CORS is configured.
Because web applications have become so complex and dynamic, an understanding of CORS is essential and typically dictates the functionality of our clients. Running into a case where CORS is not enabled is a common issue that needs to be handled.
CORS is determined by the servers that provide the files/data.
They use the different Access-Control-* headers to dictate how their data can be accessed in browsers.
The same-origin policy only applies to the client.
If there is a resource you need where CORS isn't enabled,
you can access it using your server and then respond from your server to the client.
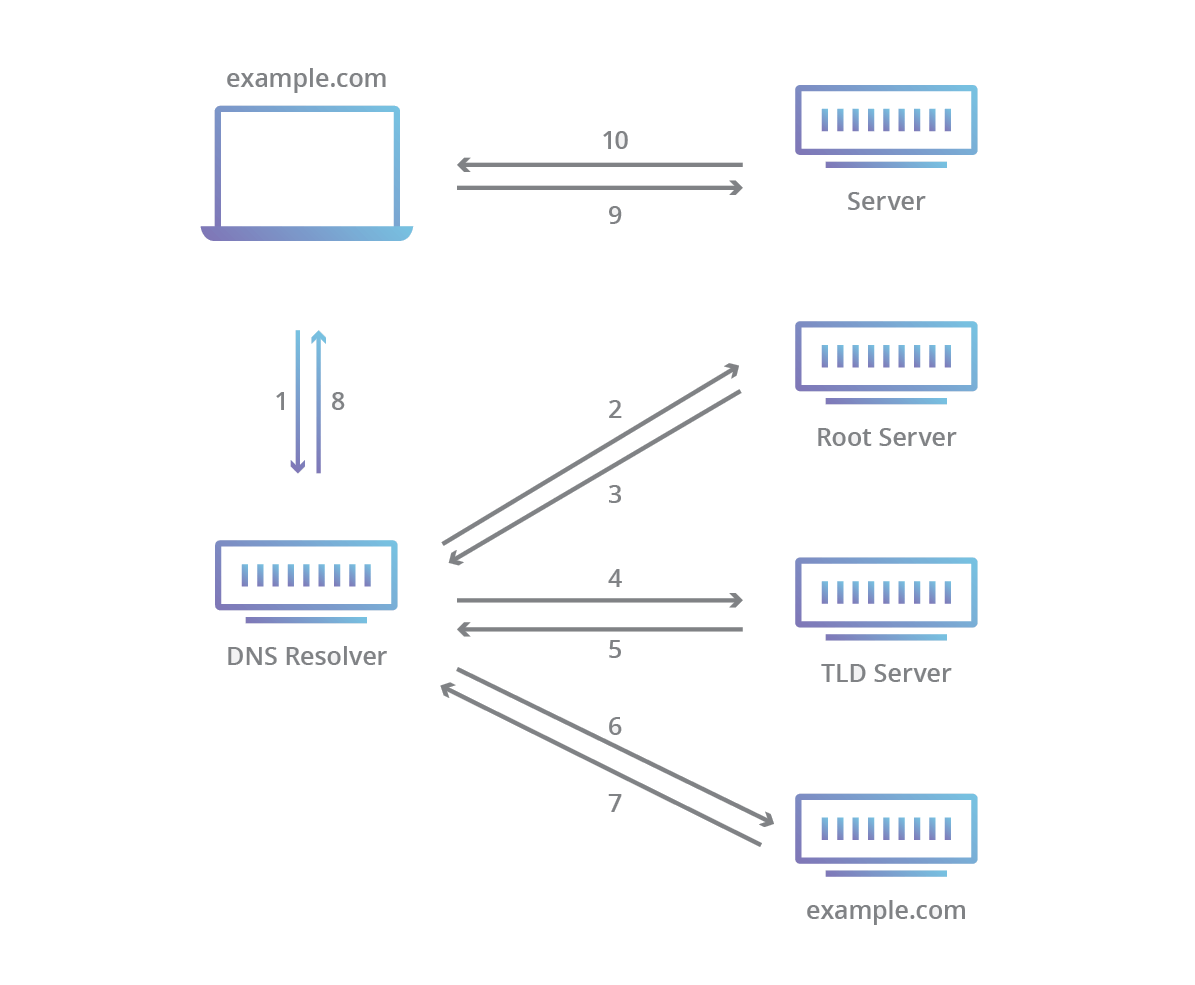
This question looks to see if you understand the fundamentals of the internet and how DNS works.
A URL is just a human-readable string to remember a website. Behind the scenes, clients/servers actually connect via an IP address, and there are a series of steps taken to translate a domain name to an IP.
The series of steps that are followed until the IP address is discovered:
- The user enters a URL.
- The client checks to see if they have the IP address cached locally that matches this URL.
- Then a resolving nameserver is queried for the IP address. This is often your internet service provider (ISP). If it does not have the IP cached, it will then go through the process to find it for you.
- The resolving server queries the root server which responds with the address of the Top Level Domain (TLD) server (such as .com or .dev), which stores information for all of its domains.
- The TLD server is queried and responds with the nameserver that stores the IP address of the domain we want (the domain's nameserver).
- The domain's nameserver (called the authoritative nameserver) is queried for the IP address of the domain we're requesting.
- The IP address is returned to the resolving nameserver which passes it to the client and can communicate with the server through the IP address matching the domain.
Before you begin optimizing your site, the first thing you need to do is diagnose the site's issues. This likely requires you to get into the browser developer console and check network requests (time they take, payload sizes, headers used) and also look at performance charts of your code.
Apps are slow either because they take too much time to get the files/data they need to run, or the code itself has bad performance. To optimize your site, the solutions typically fall under three categories:
- Reduce the amount of bytes sent from a server
- Download the right resources at the right time
- Reduce expensive / long operations
Ways to speed up your application include:
- Compress your static files and minify code: Reduce the amount of data that needs to be sent to the browser.
- Cache static files correctly in the browser: This will speed up subsequent trips to the site. You must use the appropriate headers (etags and cache control) so the browser knows how long to store files.
- Use a CDN to cache static files: This has a few benefits: 1) It allows you to put files closer to your users 2) It allows you to spread out network requests (most modern browsers only allow six concurrent requests to a single domain) 3) Users may have a required file already cached from a CDN 4) Reduces load on your server
- Optimize images: Make sure images are an appropriate size for how they are used on the page. Images are still just static assets, so we must make sure they cache correctly, use compression, and are served from a CDN.
- Load only the content necessary for a page and prioritize above the fold: You can chunk your JavaScript so it only loads what a page needs. For content on the page, you can lazy load it and show it only when necessary. For example, only download images when they come into view.
- Minimize redirects: Sending a user through multiple URLs will ultimately slow down the time it takes for them to get to the page.
- Progressive rendering: Instead of waiting for the entire data of the page to load, treat it as separate parts, and display each piece as their data is received. This can require the server to expose better API endpoints or the client to call them correctly.
- Reduce API payload size: The less data that is sent through the wire, the faster the page can load.
- Use SSR or SSG: Using server rendering or static page generation allows you to send content that a user can view without needing the entire JS bundle to download first.
- Minimize time to first bite: Fix any network issues and use
dns-prefetch. - Minimize slow operations: This can be either on the server or the client. For slow server calculations or database queries, you can cache the result in an in-memory storage like Redis.
- Handle browser events effectively: Poor event handling can grind an app to a halt. For example, if you have an
onscrolllistener, use a throttle to minimize the number of callbacks that are executed.
A question like this is meant to generate a discussion more than to elicit a specific answer. They want to hear what frameworks you have used and the opinions you have about them (pros and cons). They also want to see if you understand modern web development and how applications are built in the real-world.
A very important note: don't mention a framework unless you are prepared to discuss it and compare it to other frameworks. An interviewer isn't looking to see if you have tried every single technology. They are trying to see if you understand modern web development and justify the design decisions that you have made. You can briefly mention something like "I tried Angular for a simple project, but really focused on React afterward because I like how React...". But if you only know React (or any other single framework), really hone in on what benefits you think it provides.
For example, let's consider React.
Pros
- Component architecture
- Flexibility
- Focused on being as close to JavaScript as possible (minimal special syntax)
- Make complex applications feel simpler and easy to manage
- Single responsibility principle. It only focuses on the view / presentation layer, and the developer chooses how to handle other aspects of the app (ie. data).
- Strong community
- Applications are fast (although other frameworks have gained ground and even surpassed React's performance)
- Engaged core development team
- Commitment to constantly evolving the library but with a focus on backward compatibility
- Cross-platform with React Native
Cons
- Challenging handling of
this - SSR can be difficult
- Unopinionated. Because of React's flexibility, it can also hurt productivity because teams are required to pick their own patterns and libraries, whereas other opinionated frameworks enforce you build an app a certain way
- Reliant on the community for solutions since they aren't all baked into the core library
- Backed by a big tech company (some developers don't want to feel bolted to the whims of an entity like Facebook)
- It was one of the first compnent libraries, so it has some old patterns that newer libraries have improved
Immutable data has been growing in popularity with JavaScript developers. It means that once a variable or object is declared, it can't be altered or updated. This gives us increased stability and confidence in the state of our application.
If an object is mutable, this means that it can be modified after it is created.
Advantages of Immutability
- Simplified programs without fear of objects evolving or changing through a program's lifetime. If we pass an object around to different functions or different threads, we know it won't change at any point.
- Change detection. In JavaScript, objects are stored in variables as pointers. If we create a new object, it takes on a new memory address and thus a new pointer which allows us to know data has changed. On the other hand, if it were mutable and we alter an existing object, we will have the same pointer and would have to inspect every property to determine if there was an update.
- Better memory management. We can cache an object in memory and use this single copy as much as needed because all functions know they're accessing a read-only copy of the same data.
- Optimize CPU, memory, and rendering. If we only need to maintain a single copy of any object, we can share it everywhere to prevent any recalculations based on the data, which will only be triggered if a new object is created.
Downside of Immutability
- It's easy to mess up immutability in JS.
If you're relying on immutability but someone implements it incorrectly, it can cause challenging bugs.
One common example of this is using a spread operator
...which only makes a shallow copy, and nested objects can still be altered. - If you use immutable objects that are frequently destroyed and recreated for updates, it can decrease performance when compared to just mutating an object's property.
A key takeaway is that immutability can either help or hurt performance. If you want to enforce it strictly, it's usually best to use a library that is optimized and also enforces immutability effectively.
Immutability means that if we want to update a value, we create a new variable that contains the new value instead of changing a previously declared variable. Immutability is a core pattern in functional programming, and it gives us more confidence in our code because we know data cannot change throughout the lifetime of the program.
JavaScript doesn't offer immutable arrays or objects by default, but there are functions we can use to prevent objects from being altered and patterns we can follow to prevent data from being mutated. Strings in JavaScript are immutable.
Some examples of maintaining immutability in JS are:
Note that Object.assign and the spread operator just make a shallow copy of the object. If you have nested arrays and/or objects, they will still point to the original value.
JavaScript also offers a lower-level configuration of objects.
You can use Object.defineProperty to set the CRUD access on individual properties.
Setting writable: false means that you can't change the value of a property,
and setting configurable: false means you can't change the type or delete it from the object.
You can use Object.preventExtensions to block an object from adding new properties.
You can use Object.seal which is the same as Object.preventExtensions, but it also sets all the properties to configurable: false.
You cannot add new properties, change the type of existing properties, or delete properties.
Using Object.freeze gives you the highest level of immutability.
You cannot add, change, or delete properties.
Before the modern internet, websites were multi-page, and each page would load independently. When you clicked a link, you would navigate to this new page and the server would send its HTML, and your browser would need to download the JS and CSS required for displaying that page.
Single page applications interact with the browser to dynamically rewrite a page's HTML instead of reloading the page and downloading new HTML from a server. It instead requests only the data needed to populate a new URL.
The name "single page" means that the page is only loaded once, and subsequently receives all the JavaScript and CSS code which allows it to build UI entirely on the client. This can offer big performance improvements because it only needs data to load new pages instead of loading an entirely new HTML document. It will also have all the necessary JS and CSS and won't need to load those each time (or will only need to download small incremental chunks to render a new URL).
Not only does it improve performance on the client, but it also reduces the load on the server. The backend becomes more focused on simply being an API and passing data as JSON to the frontend.
- Client-side rendering: CSR means we render our applications entirely in the browser.
When a page is first loaded, an empty HTML document is passed to the client with a
<script>tag that retrieves JavaScript. Once this JavaScript loads, it builds the HTML for the page. CSR can be great for fast connections, but can produce a white stagnant screen if a connection is slow. CSR has been criticized for being bad for SEO because it requires the web crawler to be able to effectively run the JavaScript to build the page. - Server-side rendering: When the user requests a URL, the server generates the HTML for the first page load, and all the JS and CSS files are passed down as well. Once on the client, the additional pages behave as a single page application. This is better for slow connections because the initial work is done on the server and provides an initial page without needing to download and execute JavaScript files. This also helps with SEO because the web crawler receives a full page at the initial request.
- Static site generation: Pages of a website are built as static HTML files before deploying. This is the fastest of the three methods because the files are pre-built and can be cached in a CDN which means there is no wait time for a server to render them, and they can be sent to the client very quickly. Once the initial HTML is loaded, it is passed the JS and CSS files and often functions as a single page application after this.
Since ES2015, new features have been routinely added to the JavaScript specification. Unfortunately not all browsers implement the new features, or our users are still using old browsers. To allow developers the ability to use the new features and be compatible with all browsers, we use polyfills and/or transpile our code.
A polyfill is a piece of code that implements new JavaScript features in older ES5 JavaScript syntax that is compatible with more browsers.
For example, we can use a polyfill for the Promise object to use promises in any browser.
Another option to use new features and syntax is to transpile code.
Webpack or another bundler takes our modern code and transforms it into a version that all browsers can read.
For example, if you tried to use the spread operator ..., it would throw an error in an old browser.
Strict mode was added in ES5 as an optional opt-in feature.
It is enabled by adding the string 'use strict;' to the top of a file or function.
Strict mode is meant to make our code safer and more robust.
ES2015 modules (code using the import/export syntax) are automatically in strict mode.
The overall goal is to make JavaScript more secure, efficient, and prepared for future updates.
The advantages of strict mode are:
- Eliminates some silent JS errors by
throwing them instead - Removes the ability to assign a variable without being declared (previously assigning a variable without
varjust became a global variable) - Makes JS more secure about how it handles
this - Function parameter names must be unique
- Simplifies the usage of
evalandarguments, which allows for optimizations - Removes the ability to use features that are generally regarded as "bad"
- Paves the way for new JavaScript features by disallowing future keywords such as
privateandinterface
A JavaScript program executes exactly in-order on a single main thread. This means that code will run line-by-line synchronously. When our program encounters a synchronous function, it will add it to the call stack and the functions at the top of the call stack will run first. If a function takes a long time to finish, the following function must wait for it to complete before it can execute. This means long synchronous functions can cause our app to pause and appear frozen if not handled correctly.
JavaScript also has the concept of asynchronous functions.
This is code that is handled off the main thread, and then the result is passed to a callback or a resolve/rejected Promise.
This callback or Promise handler is passed to the event queue, and once the call stack is empty, the event loop will begin passing items from the event queue to the call stack.
Each callback will then be executed in order as it is popped off the stack, and the async function response is passed as its argument.
Asynchronous functions prevent the main thread from being blocked and allow us to perform expensive operations in a separate thread, or to wait for the result of a side effect and continue execution of the main program.
Examples of common asynchronous functions include API calls, database queries, file system I/O, and waiting for the resolution of a setTimeout call.
We can't discuss asynchronous JavaScript without going deeper into the Promise object and the async/await syntax.
A Promise is the most common way to handle the response from an asynchronous function, and declaring a function as async means that JavaScript will just return a Promise from that function automatically.
When we have an asynchronous function that returns a Promise, we can move past it and continue execution of the code on the main thread without blocking our program, and using the then method or await keyword allows us to handle the result of an asynchronous function after in completes.
Debugging is an inevitable part of coding, and there are claims that we spend anywhere from 20-90% of our time debugging. Because of this, companies want to be confident that you can do it effectively, especially if there is a bug that is in production affecting real users.
Debugging can appear in interviews in a few ways:
- Discuss your process of debugging
- Tell me about a time you debugged a difficult issue
- Be given a program and asked to debug and/or refactor it
Often this isn't one of those questions that has a "right" answer, but it's typically more of an open discussion, intended to understand your thought process and experience.
Possible points to mention:
- Using
console.log. There isn't anything wrong with using this, although some people like to frown upon it. If it is your preferred method, just be prepared to justify why. - Breakpoints and stepping through them in the browser
- Investigating files in the browser
- Looking at network requests and assessing the request and response content
- Debugging Node code with breakpoints through your text editor
- Using source maps for transpiled code
- Testing and how you use it to reduce bugs
- Using static type checking like TypeScript
- Using a tool like Sentry.io to capture bugs
- Investigating server logs
- Deployment and rollback process for production apps
- Determining how to reproduce a bug from production